
计算机视觉与多媒体智能计算学术研讨会

时间:2021年10月21日,14:30 --- 17:00
地点:西南交通大学九里校区5号教学楼4楼学术厅
主持人:徐常胜,中国科学院自动化研究所研究员,西南交通大学兼职教授,国家杰青,万人计划领军人才,IEEE Fellow, IAPR Fellow.
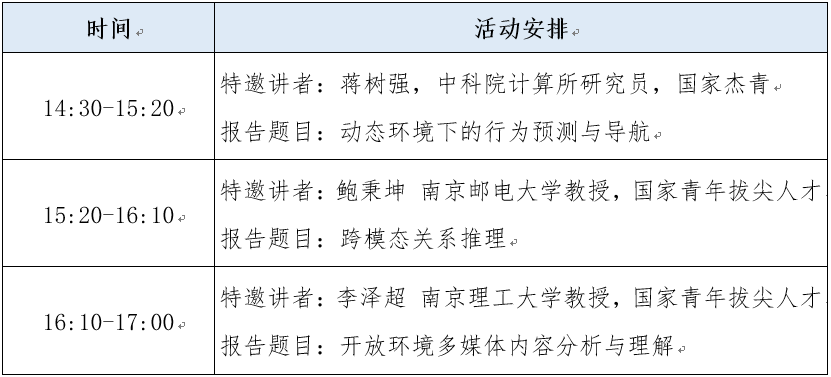
时间:2021年10月22日,16:00--17:30
地点:西南交通大学犀浦校区31524
主持人:袁召全

讲者/报告信息

讲者简介:蒋树强,中科院计算所研究员,博士生导师,国家杰出青年科学基金获得者,中科院智能信息处理重点实验室副主任,国际期刊ACM ToMM编委,任CCF多媒体专委会秘书长、CCF专委工委委员,研究方向为图像/视频等多媒体信息的分析、理解与检索技术,主持承担科技创新2030-“新一代人工智能”重大项目、国家自然科学基金等项目20余项,共在IEEE/ACM汇刊和CCF-A类会议上发表论文60余篇,获授权专利15项,先后获中国计算机学会科学技术奖、中国图象图形学会自然科学二等奖、吴文俊人工智能自然科学一等奖和北京市科技进步二等奖。
报告题目:动态环境下的行为预测与导航
报告摘要:视频内容信息量丰富,如何表示、分析、理解及应用视频依然存在很多研究挑战,特别是在真实环境中,如何适应动态环境变化、如何从已知行为预测未知行为、如何在动态环境中实现自主导航等问题都值得深入研究。报告将对视频分析与理解相关技术进行探讨,并分别介绍结合直觉与因果等因素的第一视角视频行为预测,基于层次化场景建模的视觉导航等技术。

讲者简介:鲍秉坤,南京邮电大学通信与信息工程学院教授、博士生导师,江苏省重大协同创新平台负责人。入选中组部万人计划-青年拔尖人才、江苏省杰青、江苏省双创人才。研究方向为多媒体计算、社交多媒体、计算机视觉、人工智能等。主持国家重点研发计划:科技创新2030-人工智能重大专项、国家自然科学基金重点项目等。荣获2018年度电子学会科学技术一等奖,荣获多媒体领域的ACM汇刊TOMM 2016年度最佳论文奖、IEEE MM 2017年度最佳论文奖、Multimedia Modeling 2019年度最佳论文Runner Up奖,荣获ICME 2020 Outstanding Areas Chair。担任Multimedia Systems副主编。
报告题目:跨模态关系推理
报告内容:近年来涌现很多文本与视觉上的跨模态任务,如文本图像编辑,场景图生成,视频问答等等。虽然现有模型已经具备了较强的对文本及视觉信息的感知能力,但其普遍缺乏对信息间鲁棒关系的建模,例如:物体描述与图像特征的关系,物体特征与知识图谱中节点的关系、以及同一物体在视频帧之间的时空依赖关系等。这一缺陷使得模型感知到的跨模态信息难以得到充分利用,并最终制约了模型对跨模态场景信息和语义信息等高阶信息的理解。本报告将介绍关系在跨模态任务上的表现形式,并介绍跨模态关系推理在三个代表性任务上的应用,通过跨模态关系推理,实现对模态间与模态内的对象之间的隐含关系的挖掘,最终得到更加鲁棒的特征表达,提高模型的理解能力。

讲者简介:李泽超,南京理工大学计算机科学与工程学院、人工智能学院教授、博士生导师,“社会安全信息感知与系统” 工信部重点实验室副主任,分别于2008年和2013年毕业于中国科学技术大学和中国科学院自动化研究所。研究兴趣主要是媒体智能分析、人工智能等。发表ACM/IEEE Transactions或者CCF A类会议论文60余篇;入选爱思唯尔2020中国高被引学者、2018年度“万人计划”青年拔尖人才、中国科协青年人才托举工程;获得三次省部级一等奖、2018年吴文俊人工智能优秀青年奖等;获得国家自然科学基金委企业创新发展联合基金重点支持项目、江苏省杰出青年基金资助等。
报告题目:开放环境多媒体内容分析与理解
报告内容:图像视频大数据智能分析与理解在多种实际应用中具有至关重要的作用,比如无人驾驶、网络空间内容安全以及社会公共安全等。然后实际情况下训练数据往往是受限的。为此,我们研究了开放环境下智能图像内容理解问题,主要是半监督和弱监督条件下的图像内容分析,提出了半监督特征学习方法,提出了分析用户信息的张量分解模型以及基于锚体的张量分解模型,高效的融合社交网络图像的多源异质信息,提出了深度协同因子分解模型,将图像和标签映射到统一空间,同时解决图像标注、标签优化、基于内容的图像检索以及标签扩展等多种任务。

讲者简介:刘偲,北航副教授,博导。曾主持国家优秀青年科学基金。博士毕业于中科院自动化所,曾于新加坡国立大学任研究助理和博后,曾任微软亚洲研究院(MSRA)铸星计划研究员。研究方向是跨模态多媒体智能分析(跨模态包含自然语言,计算机视觉以及语音等)以及经典计算机视觉任务(目标检测、跟踪和分割)。共发表了CCF A类论文50余篇,其研究成果发表于TPAMI、IJCV和CVPR等。Google Scholar引用7600+次。2017年入选中国科协青年人才托举工程。获CCF-腾讯犀牛鸟专利奖、吴文俊人工智能优青奖、CSIG石青云女科学家奖。获ACM MM最佳技术演示奖和最佳论文奖各一次,以及IJCAI 最佳视频奖。指导学生获ChinaMM 2018最佳学生论文奖和PRCV 2020最佳论文提名奖。多次带领北航大三、大四本科生发表一作CVPR、AAAI和ACM MM 论文。 带领学生获得10项CVPR、ICCV、ACL等国际顶级竞赛冠军。并指导学生获得北航冯如杯一等奖。主办了ECCV 2018、ICCV 2019、CVPR 2021‘Person in Context’workshop,在学术界和工业界均有较大影响力。担任中国图象图形学学会理事、副秘书长。多次担任ICCV、CVPR、ECCV等顶级会议领域主席(AC)。研发的技术服务于十余家互联网领军企业,如阿里、腾讯、华为、商汤、依图和小米等。个人主页:http://colalab.org/ 。
报告题目:跨模态分析
报告内容:围绕跨模态方面,我将介绍三方面的工作。1)视觉关系分割 (Human Relation Segmentation)是我们提出的新任务,是人-物关系检测任务的细粒度形式。 该任务旨在预测人体与周围实体之间的关系,人和实体均以像素级掩码的形式进行表达。此外,我们为这项新任务收集了一个新的数据集,并提出同时匹配和分割的框架作为 HRS 任务的解决方案。2)指代分割(referring segmentation)任务是指给定自然语言表达式和图像/视频,生成语言表达对应的实体的像素级掩码。我们提出了一种跨模态渐进理解(CMPC)方案来有效模仿人类行为,并将其实现为 CMPC-I(图像)模块和 CMPC-V(视频)模块,以改进参考图像和视频分割模型。3) 远程视觉定位(REVERIE) 任务需要根据语言指令导航到远程对象并对其进行定位。其难点是智能体需要在环境内对目标进行探索。我们我们提出了一个融合常识的实体关系推理模块来学习房间和对象实体之间的内外部相关性,以便智能体在每个视点采取适当的行动。
相关文章
STRL 2024(2024年国际人工智能顶会IJCAI下属Workshop)征稿通知
会议名称:第三届时空推理和学习国际研讨会(国际人工智能顶会IJCAI 2024下属Workshop之一)会议官网:https://www.lirmm.fr/strl2024/会议时间:2024年8月(具体日期待定)会议地点:韩国济州岛参……
【学术讲座】开放世界中机器学习的自然鲁棒性
时间:2023年12月26日16:00-18:00地点:犀浦校区X31541报告厅主讲人:魏鸿鑫 主讲人简介: 魏鸿鑫,现任南方科技大学统计与数据科学系助理教授,博士生导师。他于2023年在新加坡南洋理工大学计算机科学系完成博……
利兹大学张旭博士学术报告通知
题 目: AI and Blockchain Empowered Metaverse for Web 3.0: Vision and Our Practices时 间: 2023年12月20日(星期三)16:00点地 ……