
学院6篇论文被国际顶级会议ACM Multimedia 2024录用
学院6篇论文被国际顶级会议——第32届国际多媒体学术会议(ACM International Conference on Multimedia,简称ACM MM)录用,本届会议将在澳大利亚墨尔本举行。论文均是以西南交通大学为第一署名单位。在全球4385篇有效投稿中,1149篇论文被录用,接收率为26.2%。国际多媒体学术会议(ACM MM)是计算机学科公认的多媒体领域和计算机视觉领域的国际顶级会议,被中国计算机学会(CCF)列为A类会议。这是学院连续九年在CCF A类国际一流会议发表高水平论文,标志着我院在人工智能和计算机视觉领域的研究成果得到了国际同行的认可。
论文《Efficient Single Image Super-Resolution with Entropy Attention and Receptive Field Augmentation》(作者:Xiaole Zhao, Linze Li, Chengxing Xie, Xiaoming Zhang, Ting jiang, Wenjie Lin, Shuaicheng Liu, Tianrui Li)第一作者为赵小乐老师,硕士生李林泽为第二作者,李天瑞教授为通讯作者。轻量级超分辨重建在卫星遥感、画质提升等领域具有重要作用。论文提出了新的熵注意力和偏移大核注意力,并设计了一个高效的轻量级超分辨方法(EARFA),用于平衡超分辨性能和模型开销。论文从信息论的角度重新考虑注意力机制,结合高斯分布下的微分熵,提出了一种轻量级且高效的熵注意力机制,可以为模型提供更多信息进行精确重建。此外,论文还将通道偏移引入大核注意力,在不增加额外参数量的条件下进一步增强大核注意力机制的有效感受野。所提EARFA模型以适量的开销,在轻量级和超轻量级超分辨任务上都表现出最优的重建效果。

图1. 轻量级超分辨方法(EARFA)的框架
论文《Rethinking the Effect of Uninformative Class Name in Prompt Learning》(作者:Fengmao Lv, Changru Nie, Jianyang Zhang, Guowu Yang, Guosheng Lin, Xiao Wu, and Tianrui Li)由吕凤毛副教授、吴晓教授和李天瑞教授合作完成,吕凤毛副教授为第一作者,硕士生聂昶如为第二作者。现有的视觉语言大模型提示学习方法通常会导致学习到的提示背景过拟合于训练数据,造成大模型在零样本识别任务上的性能退化。论文针对此现象提出了一个新的见解,即类名信息不足会导致提示学习中基础类到新颖类的泛化性能下降。论文主张通过增强类名的语义丰富性来提高提示学习从基础类到新颖类的泛化性能,提出了基于信息解耦的关联提示学习(IDAPL)机制来优化可学习上下文和类名嵌入,同时对上下文通用信息和类名表示信息进行解耦,缓解了现有视觉语言大模型提示学习所带来的对基础类过度拟合的负面影响。
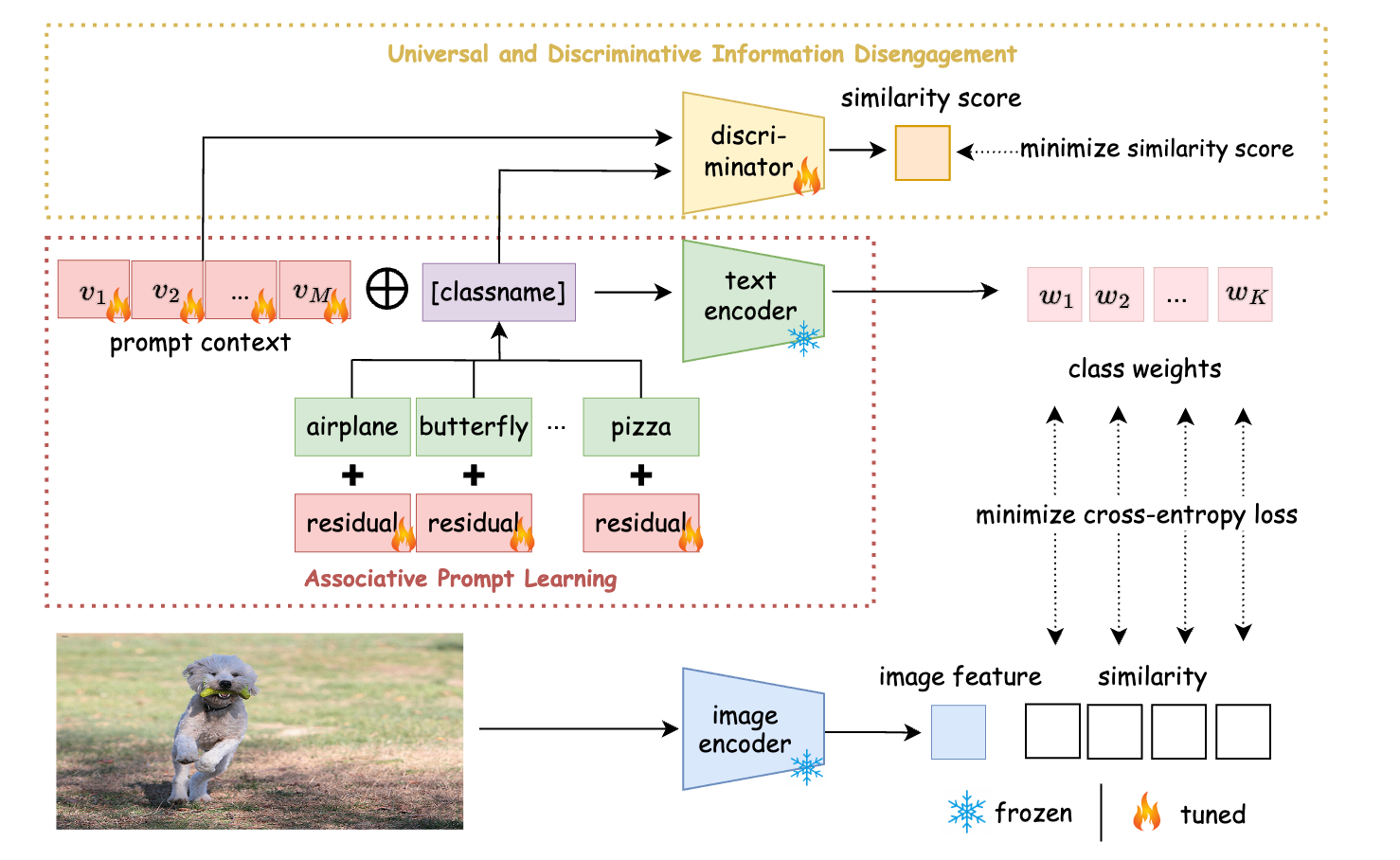
图2. 基于信息解耦的关联提示学习(IDAPL)的框架
论文《Enhancing Video Sentiment Analysis via Progressively Sentiment-Oriented Sarcasm Refinement and Integration》(作者:Junlin Fang, Wenya Wang, Guosheng Lin, and Fengmao Lv)第一作者为硕士生方俊麟,通讯作者为吕凤毛副教授。反语是一种复杂的表达现象,近年来受到越来越多的关注,特别是在视频等多模态语境中。带有反语意味的视频通常会传达出不同的情绪,甚至与它们明确传达的信息相矛盾。论文提出了渐进式面向情感的反语提炼与整合(PS2RI)框架,该框架侧重于对面向情感的反语特征进行建模,以增强情感预测。先前的工作主要集中在利用多任务学习(MTL)框架简单地建模反语和情感特征,论文发现这在反语检测任务和情感分析任务之间引入了有害的相互作用。PS2RI不是在MTL框架下简单地将反语检测和情感预测结合起来,而是在情感识别框架内迭代地进行面向情感的反语提炼和反语整合操作,以逐步学习反语感知的情感特征,而不会遭受与情感分析任务无关的信息所造成的有害相互作用。
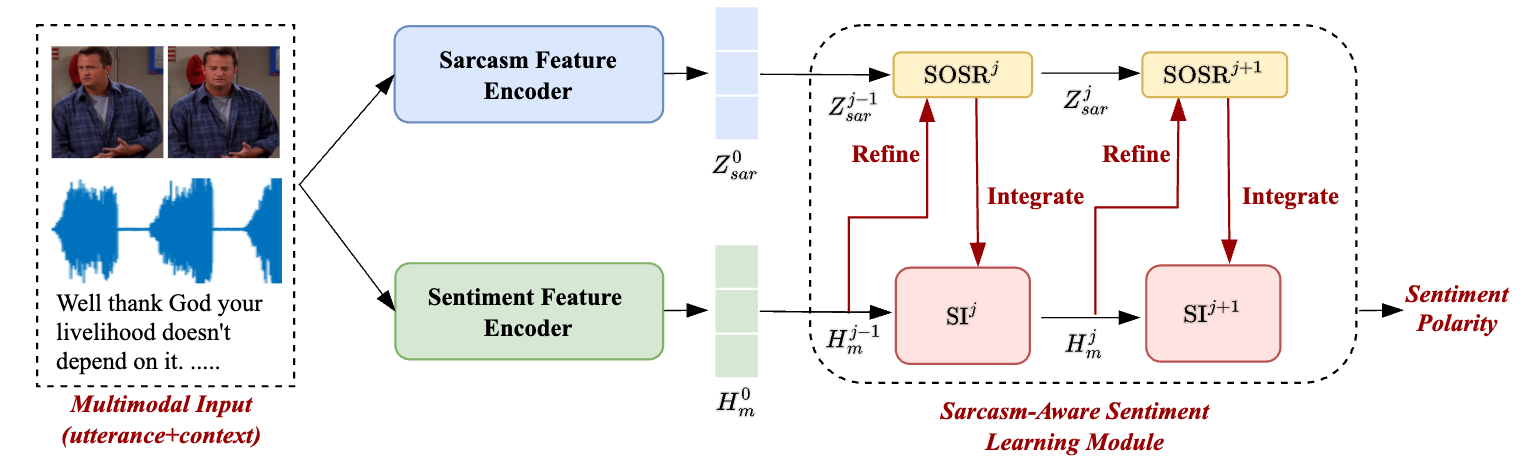
图3. 渐进式面向情感的反语提炼与整合框架
论文《MagicCartoon: 3D Pose and Shape Estimation for Bipedal Cartoon Characters》(作者:Yu-Pei Song, Yuan-Tong, Xiao Wu, Qi He, Zhaoquan Yuan, and Ao Luo)第一作者为博士生宋雨佩,吴晓教授为通讯作者。3D姿态与形状估计旨在从图像中精确建模参数化数字模型的姿态和形状参数,进而实现对图像中目标对象的三维表征。由于卡通角色在外观和姿态表达的多样性,卡通角色的3D重建面临着严峻的挑战。直接应用基于人体建模的方法处理卡通角色数据往往难以取得理想结果。论文深入剖析了数据特性差异导致性能退化的根本原因,揭示出姿态和形状学习之间的内在冲突是制约性能提升的关键因素,提出了一种创新的3D双足卡通人物估计方法,采用双分支结构,并通过特征解耦技术独立地对姿态和形状进行建模,有效缓解了两者之间的学习冲突。
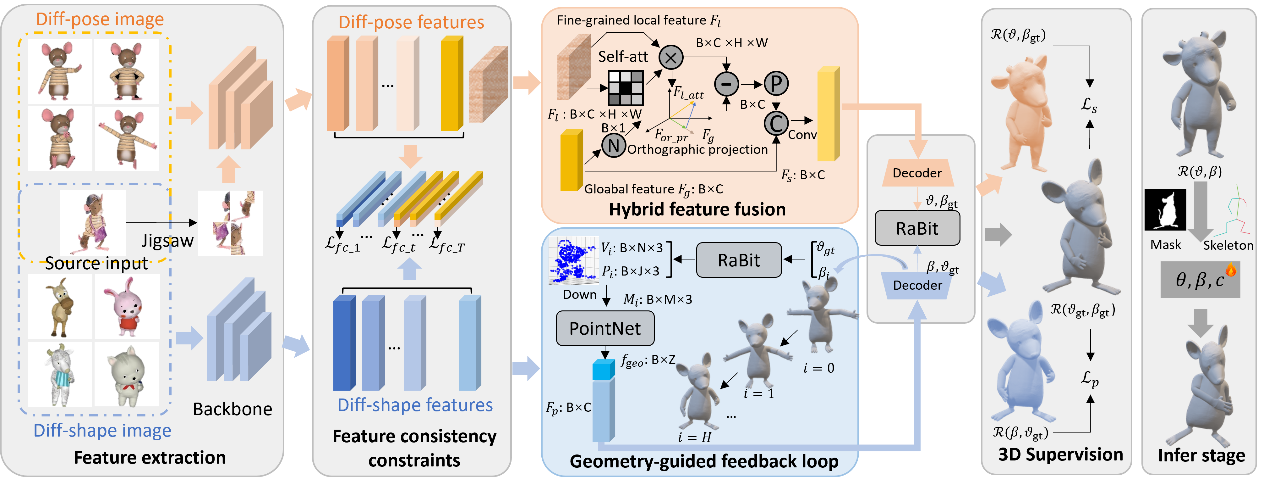
图4. 基于双分支结构的卡通角色建模框架
论文《CartoonNet: Cartoon Parsing with Semantic Consistency and Structure Correlation》(作者:Jian-Jun Qiao, Meng-Yu Duan, Xiao Wu, and Yu-Pei Song)第一作者为博士生乔建军,吴晓教授为通讯作者。卡通解析旨在识别卡通图像,分割卡通人物的身体部位。由于卡通角色的外观复杂、绘画风格抽象且多样、卡通人物结构不规则等特性,卡通解析是一项具有挑战性的任务。已有的方法主要集中于人物解析,忽略了卡通图像的特性,在卡通解析任务上性能有限。论文提出了CartoonNet方法,通过语义一致性学习和结构相关性建模缓解卡通解析面临的外观多样、结构复杂的问题。论文提出基于记忆结构的语义一致性学习方法,通过从记忆库中选取相关联的卡通样本来推理当前样本,并利用自注意力机制进行不同样本的融合学习,从而实现语义一致性。此外,论文设计了基于主体结构感知的结构关联模块,引入图注意力网络来建模卡通人物结构,捕获主体结构信息和重要连接关系,缓解卡通图像解析面临的结构复杂、抽象的问题。
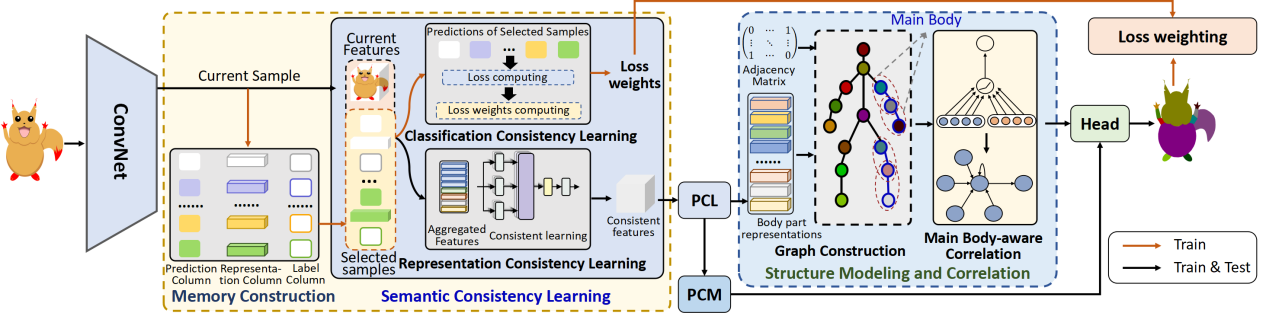
图5. 基于语义一致与结构关联的卡通解析框架
论文《CAPNet: Cartoon Animal Parsing with Spatial Learning and Structural Modeling》(作者:Jian-Jun Qiao, Meng-Yu Duan, Xiao Wu, and Wei Li)第一作者为博士生乔建军,吴晓教授为通讯作者。卡通动物解析旨在分割卡通动物的身体部位。为了应对卡通动物解析存在的类别多样、外观差异、结构复杂等挑战,论文提出了基于空间学习和结构建模的卡通动物解析方法CAPNet。空间学习策略通过可变形卷积捕获卡通动物不规则的空间特征,并利用轮廓检测和中心点预测进行辅助,捕获卡通图像复杂的空间分布信息。结构建模方法通过图神经网络建模卡通动物结构,并利用形状感知关系学习网络捕获形状信息和关联身体结构。论文基于空间和结构一致性学习策略,通过交叉注意力机制有效融合空间和结构信息,捕获不同动物种类之间的特征相关性,缓解了卡通动物类别差异导致的解析困难。
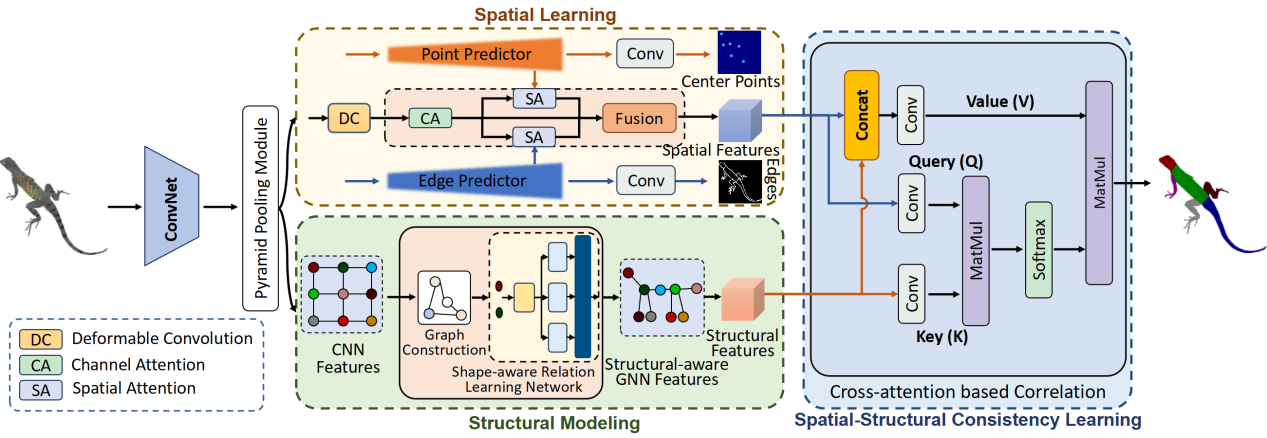
图6. 基于空间学习和结构建模的卡通动物解析框架
计算机与人工智能学院在计算机领域顶级国际会议的连续突破,尤其是今年首次在SIGIR、ICLR、WWW等国际一流会议发表论文,反映出学院在“智能引领、交叉融合”的战略牵引下,在人工智能领域取得了重要进展。
相关文章
“人工智能引领时代变革”人工智能领域创新领军工程硕博士分论坛圆满举行
为深入贯彻落实国家关于卓越工程师培养和人工智能发展的战略部署,推动人工智能赋能工程教育改革与产教融合发展,6月26日,由西南交通大学研究生院、国家卓越工程师学院主办,西南交通大学计算机与人工智能学院承办的人工智能领域创新领……
润心赋能·遇见幸福 ——"养育之慧:智慧父母课堂"第三期活动举行
由校工会、心理研究与咨询中心主办,计算机与人工智能学院工会承办的2026年春季学期“润心赋能·遇见幸福”——“养育之慧:智慧父母课堂”心理沙龙系列活动第三期于2026年6月4日下午在犀浦校区计算机学院工会职工之家如期举行。校……
计算机与人工智能学院开展本科教学巡视工作
为持续深化学校“双严”传统,筑牢本科教学质量根基,推动“以本为本、回归课堂”育人理念走深走实,计算机与人工智能学院于6月组织开展了本学期本科教学巡视工作。院长李天瑞、党委书记翟东海、副院长邢焕来深入教学一线,对《机器学习》、……